Documentation Revision Date: 2019-08-22
Dataset Version: 1.1
Summary
Canopy cover data were derived from Light Detection and Ranging (LiDAR) data, often obtained at the county-level, leaf-on agricultural imagery, and county building polygon data, when available. The input data were processed with a rules-based expert system which facilitated integration of imagery and LiDAR into a single classification workflow, utilizing the spectral, height, and spatial information contained in the datasets to estimate tree canopy cover. A 1 x 1-m pixel was identified as having tree canopy present when it (1) contained an object 2-m or higher, (2) was not a known building and/or (3) had a complex LiDAR return structure (typically trees) as compared to those with a simple return structure (typically buildings).
There are three data files provided in GeoTIFF (.tif) format, one for each state.
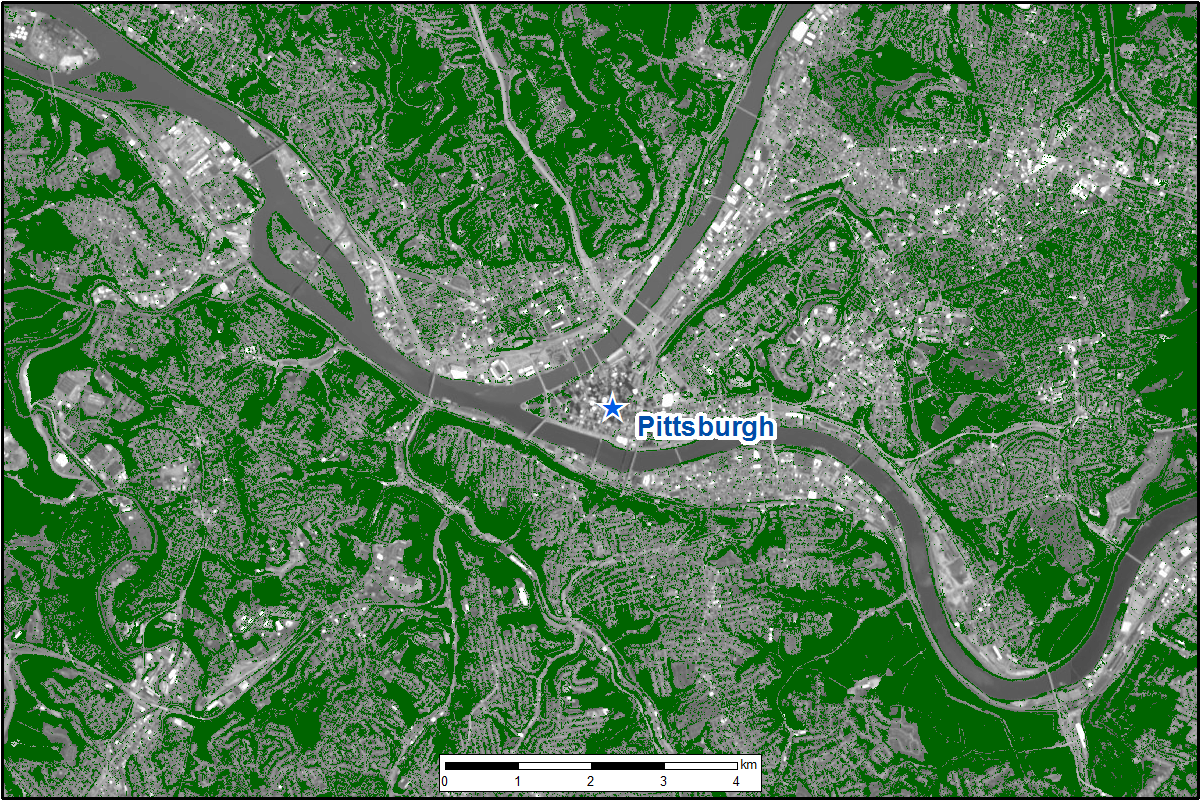
Figure 1. Estimated tree canopy cover (in green) near Pittsburgh, Pennsylvania, for the year 2008.
Citation
O'Neil-Dunne, J. 2019. CMS: LiDAR-derived Tree Canopy Cover for States in the Northeast USA. ORNL DAAC, Oak Ridge, Tennessee, USA. https://doi.org/10.3334/ORNLDAAC/1334
Table of Contents
- Dataset Overview
- Data Characteristics
- Application and Derivation
- Quality Assessment
- Data Acquisition, Materials, and Methods
- Data Access
- References
- Dataset Revisions
Dataset Overview
This data set provides high-resolution (1-m) tree canopy cover for states in the Northeast USA. State-level canopy cover data are currently available for Pennsylvania (data for nominal year 2008), Delaware (2014), and Maryland (2013). The data were derived with a rules-based expert system which facilitated integration of leaf-on LiDAR and imagery data into a single classification workflow, exploiting the spectral, height, and spatial information contained in the datasets. Additional states will be added as data processing is completed.
Canopy cover data were derived from Light Detection and Ranging (LiDAR) data, often obtained at the county-level, leaf-on agricultural imagery, and county building polygon data, when available. The input data were processed with a rules-based expert system which facilitated integration of imagery and LiDAR into a single classification workflow, utilizing the spectral, height, and spatial information contained in the datasets to estimate tree canopy cover. A 1 x 1-m pixel was identified as having tree canopy present (value=1) when it (1) contained an object 2-m or higher, (2) was not a known building and/or (3) had a complex LiDAR return structure (typically trees) as compared to those with a simple return structure (typically buildings).
Project: Carbon Monitoring System (CMS)
The NASA Carbon Monitoring System (CMS) is designed to make significant contributions in characterizing, quantifying, understanding, and predicting the evolution of global carbon sources and sinks through improved monitoring of carbon stocks and fluxes. The System will use the full range of NASA satellite observations and modeling/analysis capabilities to establish the accuracy, quantitative uncertainties, and utility of products for supporting national and international policy, regulatory, and management activities. CMS will maintain a global emphasis while providing finer scale regional information, utilizing space-based and surface-based data and will rapidly initiate generation and distribution of products both for user evaluation and to inform near-term policy development and planning.
Related Dataset:
Dubayah, R.O., A. Swatantran, W. Huang, L. Duncanson, K. Johnson, H. Tang, J.O. Dunne, and G.C. Hurtt. 2018. LiDAR Derived Biomass, Canopy Height and Cover for Tri-State (MD, PA, DE) Region, V2. ORNL DAAC, Oak Ridge, Tennessee, USA. https://doi.org/10.3334/ORNLDAAC/1538
Acknowledgements: This research was funded by NASA's Carbon Monitoring System program, Grant number NNX10AT74G.
Data Characteristics
Spatial Coverage: States in the Northeast USA.
Spatial Resolution: 1 meter
Temporal Resolution: One-time estimates
Temporal Coverage: Nominal year varies by state.
Study Area: (All latitude and longitude given in decimal degrees)
| Site | Westernmost Longitude | Easternmost Longitude | Northernmost Latitude | Southernmost Latitude |
|---|---|---|---|---|
| Delaware | -75.78998889 | -75.041475 | 39.83900556 | 38.45079167 |
| Maryland | -79.77596944 | -74.6564 | 40.25209167 | 37.70923611 |
| Pennsylvania | -81.14147778 | -74.15408889 | 43.09865278 | 38.86246389 |
Data File Information:
There are three data files provided in GeoTIFF (.tif) format with this data set which provide the estimated tree canopy coverage for each state. All files have a spatial resolution of 1 m2 and contain one band of data where a value of 0 = tree canopy not present, and 1 = tree canopy present.
| File name | Data represents conditions in the (nominal) year |
|---|---|
| treecanopy_DE.tif | 2014 |
| treecanopy_MD.tif | 2013 |
| treecanopy_PA.tif | 2008 |
File properties
| File name | EPSG code | Pixel value notes | No data value | file_size_mb | n_cols | n_rows |
|---|---|---|---|---|---|---|
| treecanopy_DE.tif | 2776 | none | 15 | 246.384 | 64,068 | 154,119 |
| treecanopy_MD.tif | 9001 | none | 3 | 1,113.10 | 406,166 | 209,447 |
| treecanopy_PA.tif | 9001 | Pixels with values of 0 within the PA state boundary should be interpreted as “tree canopy not present”. Pixels with values of 0 outside the PA state boundary should be interpreted as having “no data”. | 0 | 3,181.80 | 519,086 | 381,679 |
Application and Derivation
The approach used to generate this data set could be used to provide estimates at fine spatial resolution in other areas with LiDAR data coverage. High-resolution maps provide a valuable reference to improve the analysis and interpretation of large-scale maps produced through NASA's CMS project.
Quality Assessment
The output vector tiles from the automated system were subjected to manual edits by a team of trained image analysts operating at a scale of 1:10,000. The focus of the manual editing process was to address issues that could not effectively be automated.
Data Acquisition, Materials, and Methods
Source data for each state
| State | LIDAR data | Imagery |
|---|---|---|
| Delaware | 2014 LiDAR | |
| Maryland | 2013 LiDAR | |
| treecanopy_PA |
County-level data obtained between 2006 and 2008. The LiDAR data included a classification that identified ground points, information on the number of returns for each point, and intensity values, among others. For all the LiDAR data the point density ranged from 0.6 to 3.3 points per square meter, depending on the county and collection parameters. |
Imagery was acquired during peak leaf-on conditions in the summer of 2010 through the National Agricultural Imagery Program (NAIP) at a resolution of 1 m. The imagery consisted of 4-band (blue, green, red, near-infrared) data. |
System for Extracting Tree Canopy
The system for extracting tree canopy had to meet several criteria: 1) flexibility to account for differences in the source data, 2) yield a product with a 95% or better user’s accuracy, 3) integrate raster and vector data into a single processing environment, and 4) efficiently process large amounts of data. Based on these criteria a system was developed that centered on the eCognition software platform (Trimble, Sunnyvale, CA). eCognition’s object-based technology which enabled raster and vector data sets to be combined in a single operating environment in which rule-based expert systems could be employed to classify features based on their spectral, height, and spatial properties (O'Neil-Dunne et al., 2014).
Data were processed on a county-by-county basis. For each county the raster data sets (LiDAR and imagery) and vector data sets were loaded into an eCognition project. Building on systems developed for prior tree canopy mapping projects (MacFaden et al., 2012; O’Neil-Dunne et al., 2012), two rule-based expert systems were designed to handle each of the two data scenarios. Each rule set contained a series of tiling, segmentation, classification, and morphology algorithms designed to extract tree canopy. The purpose of the tiling operations was to break the data into smaller chunks to distribute the processing load (O'Neil-Dunne et al., 2014).
Data Processing
The LiDAR data included a classification that identified ground points, information on the number of returns for each point, and intensity values, among others. For all LiDAR data the point density ranged from 0.6 to 3.3 points per square meter, depending on the county and collection parameters.
Imagery was acquired during peak leaf-on conditions in the summer of 2010 through the National Agricultural Imagery Program (NAIP) at a resolution of 1 m. The imagery consisted of 4-band (blue, green, red, near-infrared) data.
Building polygons were used to distinguish the tree canopy from the buildings in LiDAR data. Building polygon data were available for twelve of the sixty-seven counties in Pennsylvania.
The combination of LiDAR, imagery, and building polygons lead to two data scenarios:
1) LAS LiDAR and NAIP imagery without building polygons
2) LAS LiDAR and NAIP imagery with building polygons
Each county LiDAR collection was processed to create various raster surface models. The raster cell size was set based on the average point spacing. The LiDAR data were processed to yield a raster Digital Surface Model (DSM), and a raster Digital Elevation Model (DEM) from the return and classification information contained in the LAS attributes. The DEM was then subtracted from the DSM to create a Normalized Digital Surface Model (nDSM), in which each pixel represented the height above ground. In addition to the nDSM the LiDAR data were processed to yield a Digital Terrain Model (DTM) from the last returns. A Normalized Digital Terrain Model (nDTM) was then created by subtracting the DEM from the DTM. The NAIP imagery was simply assembled into county mosaics. Building polygons were retained in their original vector format (Shapefile).
Following the county tiling operation, the rule sets followed a series of three steps:
1) A single height threshold was used to separate out tall features, defined as those objects 2-m or higher, the minimum height definition for tree canopy for this project. Included in this step was a gap filling routine designed to ameliorate the gaps in deciduous canopy stemming from the leaf-off nature of the LiDAR.
2) Tree canopy was differentiated from buildings based on a combination the imagery, LiDAR, and, if present, building polygons. This step is where the main differences in the two rule sets arose. The difference between the nDSM and nDTEM layers emphasized tall features with a complex return structure (typically trees) from those without (typically buildings). For counties that had building polygons, additional rules were incorporated to account for the fact that tall features within building polygons were most likely buildings, with the exception of the overhanging tree canopy. The rules in the second step consisted of simple thresholds that could be modified to account for the unique characteristics of the data sets in each county.
3) Tree canopy features were exported to a vector data set. Context-based rules were used to refine the tree and building classes based on spatial relationships. The context-based rules served to address issues of class confusion, primarily along tree/building borders. However, the rules also addressed other issues such as objects in the middle of a forest, that while sharing all the properties in the imagery and LiDAR of buildings, were unlikely to be so due to the absence of other buildings in the vicinity. Once this iterative process was completed morphology routines were employed to restructure the canopy, removing slivers and spurious objects.
Quality Assessment
The appropriate rule-based expert system was applied to the county based on the two data scenarios. As the data in each county proved to be unique, the rule-based expert system was tested, and modified accordingly on subsets of the data prior to execution. The output vector tiles were then subjected to manual edits by a team of trained image analysts operating at a scale of 1:10,000. The focus of the manual editing process was to address issues that could not effectively be automated. Following the completion of the manual edits, the data were compiled into a statewide tree canopy mosaic (O'Neil-Dunne et al., 2014).
Data Access
These data are available through the Oak Ridge National Laboratory (ORNL) Distributed Active Archive Center (DAAC).
CMS: LiDAR-derived Tree Canopy Cover for States in the Northeast USA
Contact for Data Center Access Information:
- E-mail: uso@daac.ornl.gov
- Telephone: +1 (865) 241-3952
References
MacFaden, S. W., J. P. M. O’Neil-Dunne, A. R. Royar, J. W. T. Lu, and A. G. Rundle. 2012. High-resolution Tree Canopy Mapping for New York City Using LIDAR and Object-based Image Analysis. Journal of Applied Remote Sensing 6 (1): 063567-1-063567-23.
National Agricultural Imagery Program (NAIP): https://www.fsa.usda.gov/programs-and-services/aerial-photography/imagery-programs/naip-imagery/
O’Neil-Dunne, J.P.M., S.W. MacFaden, A.R. Royar, and M.Reis. 2014. An Object-Based Approach To Statewide Land Cover Mapping. Presented at the ASPRS 2014 Annual Conference. Louisville, Kentucky, March 23-28. https://www.asprs.org/a/publications/proceedings/Louisville2014/ONeilDunne.pdf
O’Neil-Dunne, Jarlath P.M., Sean W. MacFaden, Anna R. Royar, and Keith C. Pelletier. 2012. An Object-based System for LiDAR Data Fusion and Feature Extraction. Geocarto International (May 29): 1-16. https://doi.org/10.1080/10106049.2012.689015
Dataset Revisions
|
Version |
Release Date | Description of Changes |
|---|---|---|
| Version 1.1 | 2019-09-01 | Added data for Maryland and Delaware. |
| Version 1 | 2016-07-29 | ORNL DAAC released canopy cover data for the state of Pennsylvania. |